
Remember when streaming was simple? One subscription, unlimited content, no fine print. After came the caps, the tiers, and the growing realization that you were paying more than cable ever cost.
AI tokens are following the same arc: Token caps are getting more creative, and pricing transparency barely exists. The people building with these tools every day can’t even agree on what comes next.
Here’s how AI token pricing is shifting, where the hidden cost pressures live, and what technical leaders should prepare for now.
Editor’s Note
After this article was written, Anthropic announced it would double Claude Code’s rate limits across Pro, Max, Team, and seat-based Enterprise plans, remove peak-hour throttling for Pro and Max accounts, and raise API rate limits for Opus models. This is welcome news for teams hitting the walls described in this blog, but it also proves the point: the rules change fast, and building your AI strategy around any single provider’s current pricing page is planning on sand. Read the full announcement here.
Summary
AI token costs aren’t rising in a straight line. They’re rising sideways, through caps, restrictions, and opaque usage policies that make forecasting nearly impossible. Slingshot’s technical leaders break down the real levers CIOs can pull right now: smarter model selection to stretch token budgets, API-first architectures that separate cost from seat-based limits, and early investment in local open-source models that are already rivaling top-tier providers at a fraction of the price.
AI Token Costs Are Climbing, But Not the Way You’d Expect
The streaming comparison is tempting because, on the surface, it seems to track. Early AI access felt like early Netflix: flat pricing, generous usage, and wide-open access. But the parallel breaks down fast when you look at how providers are actually managing demand.
“It’s almost like Netflix: you have access to all the shows, but you can only watch TV one hour a day,” said Chris Howard, CIO at Slingshot. “I don’t expect the monthly subscription to go up as much, but you’ll have more restrictions on the tokens you can use. The cost-per-token will have to increase.”

Rather than simply raising the sticker price, providers are layering in caps: 5-hour usage windows, weekly limits, or model-specific restrictions. You might pay for a premium seat and still hit a wall halfway through Wednesday.
Steve Anderson, Principal Developer and AWS Architect at Slingshot, agreed. “The subscriptions used to be unlimited, and then they started capping them. Soon, they added a weekly cap on top of a 5-hour cap. It’s all because it’s so early; they’re still trying to secure their footing.”
The cost isn’t climbing in a straight line; It’s climbing sideways, through restrictions that limit what your team can actually accomplish within the access they already paid for.
The Streaming Analogy Has a Hole in It
Not everyone buys the comparison. Doug Compton, Principal AI Developer at Slingshot, pushed back on the idea that AI pricing corresponds to the fragmentation of streaming services: “Unlike the wide variety of streaming options, you only have one provider if you want the best coding agent. And if you want the best, you have to pay a lot of money.”
Unlike streaming, where each platform competes with roughly comparable content, the AI model landscape still concentrates the best capabilities in a small number of providers. You aren’t subscribing to five services for variety; you’re locked into one or two because nothing else equals the output quality.
Steve acknowledged the nuance but still saw value in diversifying. “I prefer having a backup. There’s value in having a couple of different flavors of LLMs to get a mixture of bias, so you’re not running everything through the same model.”
For technical leaders, the implication is clear: this isn’t a streaming bundle problem. It’s a vendor concentration problem. And that distinction matters when you’re forecasting costs, negotiating contracts, and planning for what happens when your primary provider changes its terms overnight.
API vs. Subscription: Two AI Token Models, Two Sets of Rules
Most AI providers offer two distinct ways to access their models. Per-seat subscriptions give individual users flat-rate access with usage caps that reset in rolling windows. API access charges per token based on actual consumption, with no usage windows or caps on the bill. The API and subscription frameworks don’t just differ in cost, but also in what you’re allowed to do.
“The terms of service are different for the two offerings,” Steve explained. “There are things you can do with an API key that are prohibited if you’re using your subscription.”
Doug reinforced the distinction. “The subscription model is meant for individual use. If you want to automate some team functionality, you have to use the API.”
Chris described the management challenge from the CIO seat. “For each individual, you can assign a standard license or a premium license. The premium just adds more tokens. But we still have people on premium that run out of tokens and hit that limit for the week.”
Even the overage mechanisms don’t behave as expected. “Even if you buy additional over-usage tokens, those people still get stuck,” Chris said.
The result is a split infrastructure that’s difficult to monitor, optimize, and explain to leadership. And for organizations running several projects at once, tracking token spend at the project level is still almost impossible.
AI Token Transparency Is Still a Guessing Game
Ask any CIO what their organization spends per project on AI tools, and you’ll likely get a blank stare. The tooling simply doesn’t support that level of visibility yet.
“We have a portfolio of roughly 25 projects going concurrently,” Chris said. “Knowing how much we’re using per project or how much it costs to write the code for that project, the tools don’t really show that easily.”
And the opacity goes beyond internal monitoring. Providers aren’t making it easy to forecast costs either. “Providers market paid subscriptions as five times the usage of a normal user,” Steve noted. “But what’s a normal user? What’s your baseline?”

Doug added that Anthropic in particular has drawn criticism. “Anthropic has been very opaque with their usage policies. People are still confused; there isn’t any ‘black and white’ as to what could get you banned versus what is okay.”
This lack of clarity creates real business risk. When you can’t attribute costs, you can’t make informed decisions about scaling, staffing, or tool selection. And when the provider changes the rules mid-cycle, your budget assumptions collapse with them.
When AI Token Limits Hit, Your Team Stops
Rate limits aren’t just an inconvenience. When a developer burns through their token allocation by midweek, they don’t just slow down; they stop entirely.
Steve’s advice on how to stop burning through tokens was simple: “Stop using Opus for everything. Claude has smaller and distilled models for a reason. Learning to figure out what the appropriate model is for any given prompt will go a long way.”
Chris acknowledged the difficulty. “There’s not really great guidance on model selection. Providers don’t give you a playbook that says which model to use for each task. It’s like an art: you have to explore and figure out what works. But that takes time your team may not have.”
But Doug challenged the framing entirely, arguing that restricting model access to conserve tokens is a false economy. “If you have a software developer who’s making good money, you should allow them to use Opus the whole time. If you’re debating between the cost of your engineer sitting there unproductive versus spending an extra $15 or $20 an hour to let them work, the answer feels like a no-brainer.”
For CIOs, the real question isn’t whether to spend on AI tokens. It’s whether you have the visibility and governance to spend wisely. Without explicit policies on model selection and usage tracking, organizations either overspend mindlessly or underinvest, losing velocity.
Local AI Models and the Open-Source Escape Hatch
Here’s where we’re taking a sharp turn. If token costs keep climbing and restrictions keep tightening, is there an exit ramp?
Doug points to coding leaderboards as evidence. Open-source and open-weight models are closing the gap fast. As of writing, GLM-5.1 ranks fifth, and Kimi K2.6 ranks sixth on Code Arena, both ahead of Claude Sonnet. On BenchLM, DeepSeek V4 Pro sits at fourth.
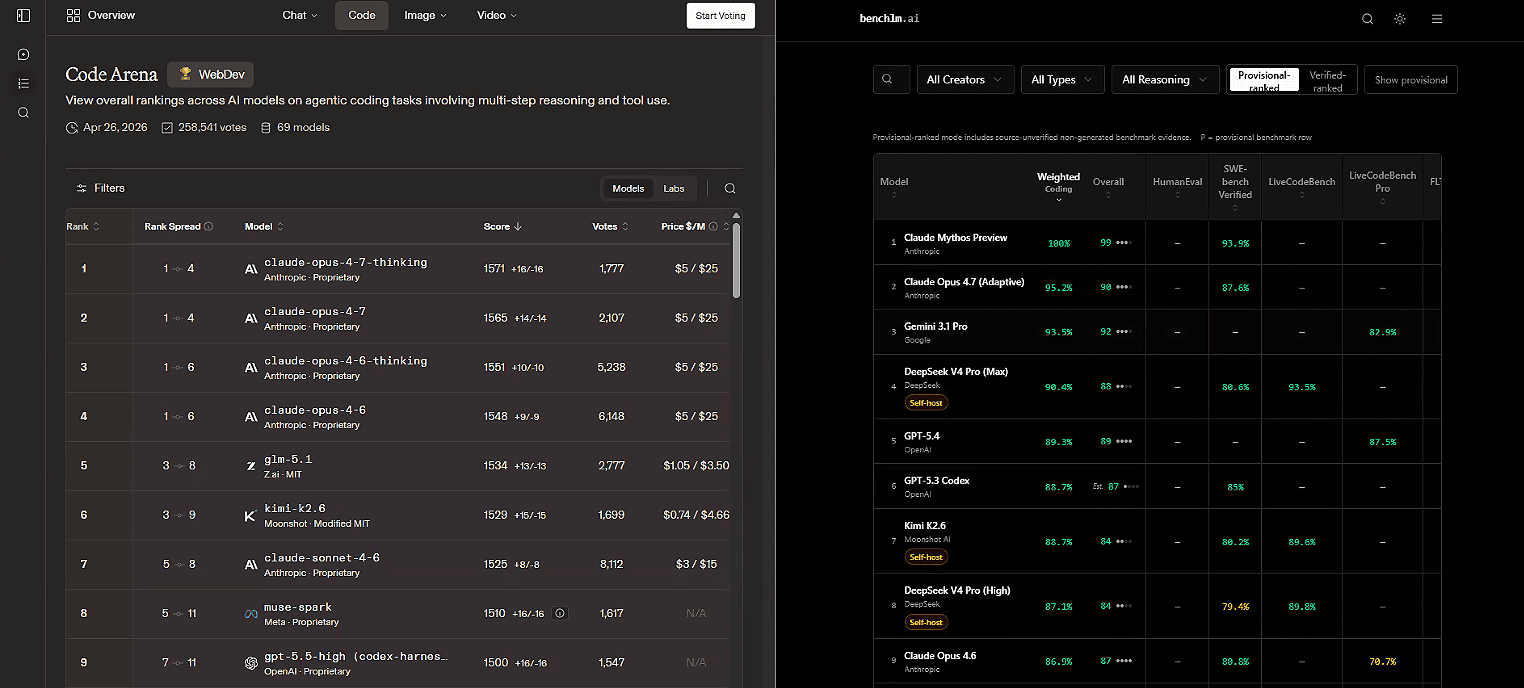
“We’re almost to the point where there are open-weight or open-source models available that are as good as the best,” Doug said. “Both open models are ahead of Sonnet, and Sonnet’s what I use for everything.”
The pricing stresses the disruption. “Kimi K2.6 is 74 cents per million input tokens and $4.66 per million output tokens. That is conservatively one-fifth the cost of Claude, if not less.”
But running these models locally still demands serious hardware. “GLM requires 750 gigabytes of memory, and DeepSeek V4 requires 1.5 terabytes,” Doug noted. “You can’t do that on consumer-grade hardware.”
Steve saw the convergence coming. “There’s already tooling in place where you could point Claude Code to a local LLM and still get the harness features you know and love.”
Doug’s prediction was definitive: “Local LLMs are the future. It will be commonplace for developers to have local LLMs within a year or two.”
But Chris pointed out a layer that technical leaders can’t overlook: “Security still matters here. If you’re considering open-source models, especially ones developed overseas, you need to understand what you’re running and where that data can go. Running locally solves a lot of that, because you control the environment and nothing leaves your network. But you still need to evaluate the model itself, the same way you’d evaluate any third-party tool before putting it in your stack.”
For CIOs evaluating their AI infrastructure roadmap, this isn’t a distant hypothetical; it’s an active consideration. Organizations that start experimenting with local model deployment now will gain greater cost flexibility, less exposure to shifting pricing terms, and more control over where their data lives. But open-source doesn’t mean zero diligence. The security evaluation still applies.
The Pricing Story Is Still Being Written
AI token economics are evolving faster than most organizations can track, let alone plan for. The streaming analogy captures the feeling of creeping cost and shrinking value, but the reality is somewhat more nuanced. You’re not choosing between five comparable services; you’re navigating vendor lock-in, opaque pricing, split infrastructure models, and restrictions that shift without warning.
The smartest CIOs aren’t waiting for the market to settle. They’re building flexibility now: diversifying model access, experimenting with API-first architectures, investing in team fluency around model selection, and keeping a close eye on the open-source models that are climbing the leaderboards faster than anyone expected.
Because the providers haven’t figured out their pricing model yet, and if you’re building your entire AI strategy on someone else’s pricing page, you’re not planning; you’re hoping.
Great Hires Still Need Tokens

Written by: Savannah Cherry
Savannah is our one-woman marketing department. She posts, writes, and creates all things Slingshot. While she may not be making software for you, she does have a minor in Computer Information Systems. We’d call her the opposite of a procrastinator: she can’t rest until all her work is done. She loves playing her switch and meal-prepping.

Expert: Chris Howard
Chris has been in the technology space for over 20 years, including being Slingshot’s CIO since 2017. He specializes in lean UX design, technology leadership, and new tech with a focus on AI. He’s currently involved in several AI-focused projects within Slingshot.

Expert: Doug Compton
Born and raised in Louisville, Doug’s interest in technology started at 11 when he began writing computer games. What began as a hobby turned into his career. With broad interests that range anywhere from snorkeling, science, WWII history and real estate, Doug uses his “down time“ to create new technologies for mobile and web applications.

Expert: Steve Anderson
Steve is one of our AWS certified solutions architects. Whether it’s coding, testing, deployment, support, infrastructure, or server set-up, he’s always thinking about the cloud as he builds. Steve is extremely adaptable, and can pick up the project and run with it. He’s flexible and able to fill in where needed. In his spare time, he enjoys family time, the outdoors and reading.
Frequently Asked Questions
Providers aren't simply raising sticker prices. Instead, they're layering in usage caps, rolling windows, and model-specific restrictions that limit what your team can accomplish within the access they already paid for. The cost is climbing sideways through restrictions, not in a straight line through price increases.
Per-seat subscriptions give individual users flat-rate access with usage caps that reset in rolling windows. API access charges per token based on actual consumption, with no usage windows or caps. The two models also differ in terms of service: automation and team-level workflows typically require API access, while subscriptions are designed for individual use.
The most immediate lever is smarter model selection. Not every task requires the most powerful (and most expensive) model. Using smaller, distilled models for routine prompts and reserving top-tier models for complex work stretches token budgets significantly. Teams also benefit from clear internal policies on which model to use for which task.
Open-source and open-weight models are closing the gap fast, with several now outranking top commercial models on coding leaderboards at a fraction of the cost. Running them locally gives organizations more control over data and eliminates exposure to shifting pricing terms. However, local deployment requires significant hardware, and security evaluation is still essential, especially for models developed overseas.
Start by diversifying model access so you aren't locked into a single provider's pricing terms. Invest in API-first architectures that separate cost management from seat-based limits. Build team fluency around model selection so token spend is intentional, not wasteful. And begin experimenting with local model deployment to gain cost flexibility before it becomes an urgent need.